I am an assistant professor at the Technical University of Darmstadt, as well as a member of the Hessian Center for Artificial Intelligence (hessian.AI). The focus of my research is on developing efficient, robust, and understandable methods and algorithms for image and video analysis. I recently got the renowned Emmy Noether Programme (ENP) fund of the German Research Foundation (DFG) supporting my research on Interpretable Neural Networks for Dense Image and Video Analysis. Before starting my own group, I was a postdoctoral researcher in the Visual Inference Lab of Prof. Stefan Roth. Prior to joining TU Darmstadt, I was a postdoctoral researcher at the Media Technology Center at ETH Zurich working on augmented reality. I obtained my doctoral degree from ETH Zurich, advised by Prof. Dr. Markus Gross and in collaboration with Disney Research Zurich. In my doctoral thesis, awarded with the ETH Medal, I developed novel methods for motion representation and video frame interpolation.
News
Publications
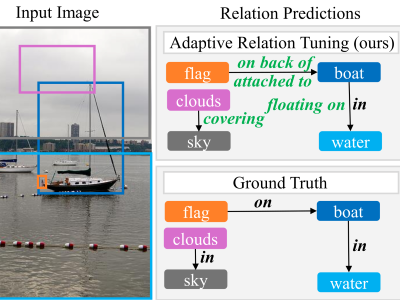 | ART: Adaptive Relation Tuning for Generalized Relation DetectionG. Sudhakaran, H. Shindo, P. Schramowski, S. Schaub-Meyer, K. Kersting, S. Roth 2025 ICCV
Preprint (arXiv) | Code |
 | Motion-refined Dinosaur for Unsupervised Multi-Object Discovery,X. Gong*, O. Hahn*, C. Reich, K. Singh, S. Schaub-Meyer, D. Cremers, S. Roth 2025 ICCV Workshop: Instance-Level Recognition and Generation (ILR) (Oral Presentation)
Preprint (arXiv) | Code |
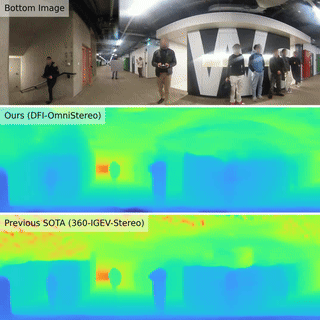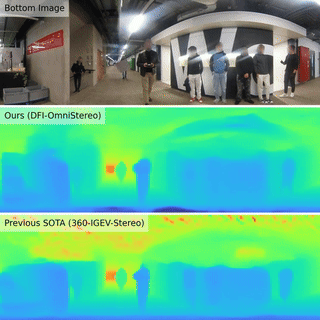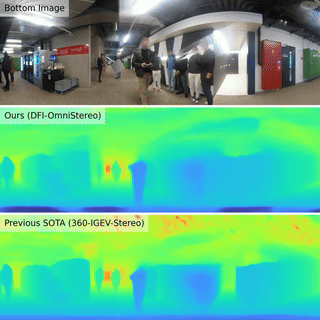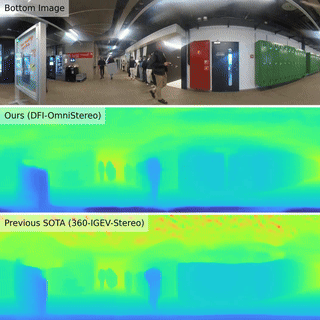 | Boosting Omnidirectional Stereo Matching with a Pre-trained Depth Foundation ModelJ. Endres, O. Hahn, C. Corbière, S. Schaub-Meyer, S. Roth, A. Alahi 2025 IROS
Preprint (arXiv) | Project page | Code |
 | Efficient Masked Attention Transformer for Few-shot Classification and SegmentationD. Carrión-Ojeda, S. Roth, S. Schaub-Meyer 2025 GCPR
2025 ICCV Workshop: Representation Learning with Very Limited Resources: When Data, Modalities, Labels, and Computing Resources are Scarce (LIMIT)
Preprint (arXiv) | Project page | Code |
| Disentangling Polysemantic Channels in Convolutional Neural NetworksR. Hesse, J. Fischer, S. Schaub-Meyer, S. Roth 2025 CVPR Workshop: Mechanistic Interpretability for Vision
Preprint (arXiv) | Code |
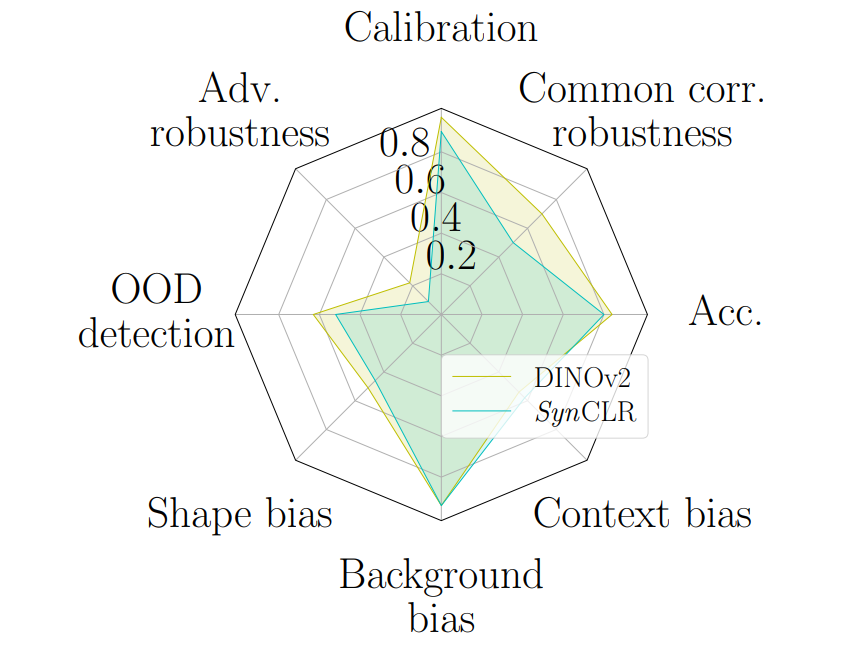 | Is Synthetic Data all We Need? Benchmarking the Robustness of Models Trained with Synthetic ImagesK. Singh, T. Navaratnam, J. Holmer, S. Schaub-Meyer, S. Roth 2024 CVPR Workshop: SyntaGen-Harnessing Generative Models for Synthetic Visual Datasets (Best Paper Award)
Preprint (arXiv) | Paper | Project page | Code |
 | Boosting Unsupervised Semantic Segmentation with Principal Mask ProposalsO. Hahn, N. Araslanov, S. Schaub-Meyer, S. Roth 2024 TMLR
2024 CVPR Workshop: Workshop on Foundation Models
Preprint (arXiv) | Paper | Code |
 | FunnyBirds: A Synthetic Vision Dataset for a Part-Based Analysis of Explainable AI MethodsR. Hesse, S. Schaub-Meyer, S. Roth 2023 ICCV (Oral Presentation)
2023 GCPR Nectar Track
Paper | Supplement | Talk video | Code |
 | Entropy-driven Unsupervised Keypoint Representation Learning in VideosA. Younes, S. Schaub-Meyer, G. Chalvatzaki 2023 ICML
Paper | Project page | Code |
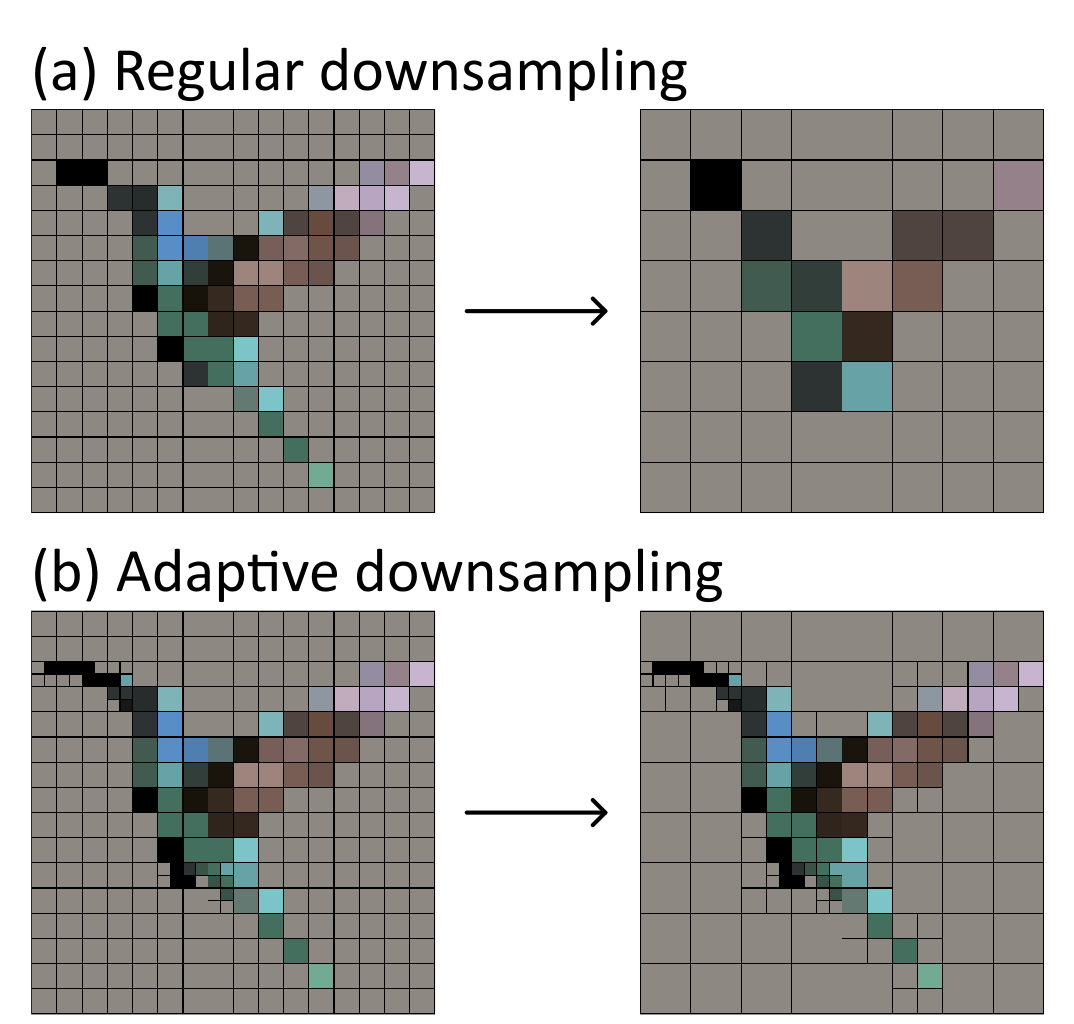 | Content-Adaptive Downsampling in Convolutional Neural NetworksR. Hesse, S. Schaub-Meyer, S. Roth 2023 CVPR Workshop: Efficient Deep Learning for Computer Vision
Paper | Supplement | Talk video | Poster | Code |
 | Style Transfer for Keypoint Matching Under Adverse ConditionsA. Uzpak, A. Djelouah, S. Schaub-Meyer 2020 3DV
Paper | Code |
 | Neural inter-frame compression for video codingA. Djelouah, J. Campos, S. Schaub-Meyer, C. Schroers 2019 ICCV
Paper | Supplement |
 | PhaseNet for Video Frame InterpolationS. Meyer, A. Djelouah, B. McWilliams, A. Sorkine-Hornung, M. Gross, C. Schroers 2018 CVPR
Paper | Supplement | Video | BibTex |
 | Phase-Based Modification Transfer for VideoS. Meyer, A. Sorkine-Hornung, M. Gross 2016 ECCV (Oral Presentation)
Paper | Video |
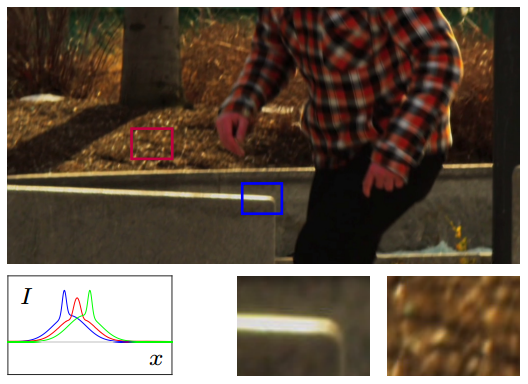 | Phase-based Frame Interpolation for VideoS. Meyer, O. Wang, H. Zimmer, M. Grosse, A. Sorkine-Hornung 2015 CVPR (Oral Presentation)
Paper | Supplement | Video | Code |



{kind=link}




